Prognozowanie danych w Google Analytics 4
Zbieranie jakościowych informacji pozwala na szersze zastosowanie danych wykraczające poza standardowy paradygmat myślenia o tym, w jaki sposób można analizować rzeczywistość, a co za tym idzie, między innymi cyfrowy biznes. Jedną z możliwości jest prognozowanie wyników, technika umożliwiająca przewidywanie przyszłości w stosownym horyzoncie przy zachowaniu odpowiednio wcześnie ustalonych reguł. W jaki sposób to można wdrożyć dla e-commerce przy użyciu Google Analytics 4?
Czego nauczysz się z tego artykułu?
- Co to jest prognozowanie, dlaczego jest to ważne dla firm i jakie techniki są najczęściej używane do prognozowania w biznesie, takie jak metody statystyczne, sondaże rynkowe, prognozowanie oparte na modelach przyczynowych, analiza szeregów czasowych czy metody oparte na sztucznej inteligencji
- Dowiesz się o specyfice prognozowania w kontekście marketingu i biznesu, jak te dwa obszary się przenikają i szczegółowo o wyzwaniach związanych z prognozowaniem wyników w marketingu
- Zrozumiesz, w jaki sposób działa prognozowanie w narzędziu Google Analytics 4, jakie metryki predykcyjne są tam dostępne i jakie warunki muszą być spełnione, aby skutecznie trenować modele prognozujące
Spis treści
Co to jest prognozowanie? Dlaczego jest ważne? Jak to firmy robią?
Prognozowanie to termin, który opisuje proces używania danych do przeniesienia wzorców i trendów w przyszłość. Jest to umiejętność przewidywania przyszłych zdarzeń, potrzeb lub zachowań na podstawie informacji, które już posiadamy. W kontekście biznesu, prognozowanie pozwala na tworzenie modeli i scenariuszy, które pomagają firmom przewidzieć przyszłe wyniki, a także zidentyfikować potencjalne możliwości lub zagrożenia. stanowi fundamentalne narzędzie dla strategicznego zarządzania firmą. Umożliwia identyfikację trendów, które mogą mieć wpływa na jej funkcjonowanie w przyszłości. Przewidywanie przyszłych wyników, czy to sprzedaży, popytu czy sytuacji na rynku, pozwala firmie przewidywać swoje potrzeby, planować strategie i podjąć decyzje, które pomogą jej osiągnąć cele w przyszłości.
Prognozowanie jest tak szerokim pojęciem, że obejmuje wiele technik, ale skupmy się na kilku najbardziej popularnych, które opierają się na matematyce, statystyce i socjologii:
- Proste metody statystyczne: Prosta metoda statystyczna, jak linia trendu, polega na dopasowaniu linii do historycznych danych w celu wyznaczenia przyszłych kierunków trendów. Inną prostą metodą jest średnia ruchoma, która polega na obliczeniu średniej z określonej liczby ostatnich obserwacji. Te metody są łatwe do zrozumienia i implementacji, ale mogą nie być wystarczająco skuteczne, kiedy dane są zmiennym i mają skomplikowane wzorce sezonowe.
- Sondaże i badania rynku: Czasami firmy stosują techniki prognozowania oparte na badaniach rynku, takie jak ankiety, wywiady czy grupy dyskusyjne, aby przewidzieć popyt na nowy produkt lub usługę. Metoda ta polega na bezpośrednim zapytaniu klientów o ich plany i przyzwyczajenia zakupowe.
- Prognozowanie oparte na modelach przyczynowych: Inne techniki prognozowania polegają na użyciu modeli przyczynowych, które zakładają istnienie zależności między danymi, które chcemy przewidzieć, a innymi danymi. Przykładem jest regresja. Można stwierdzić, że sprzedaż lodów w upalny dzień jest zależna od temperatury. Poprzez regulację różnych zmiennych, takich jak temperatura, możemy przewidywać przyszłą sprzedaż lodów.
- Analyza szeregów czasowych: Techniki te analizują dane historyczne, aby znaleźć ukryte wzorce i trendy, które można następnie wykorzystać do prognozowania przyszłości. Przykładowo, popularny model ARIMA (ang. AutoRegressive Integrated Moving Average) jest często stosowany do analizy szeregów czasowych.
- Metody oparte na sztucznej inteligencji: Algorytmy uczenia maszynowego, takie jak sieci neuronowe, lasy losowe i algorytmy boostingu gradientowego, stają się coraz częściej stosowane w prognozowaniu biznesowym. Są w stanie przetwarzć ogromne ilości danych i identyfikować skomplikowane wzorce, które mogą umknąć prostszym technikom prognozowania.
Ostatecznie, efektywność prognozowania jest zależna od kontekstu i specyfiki danej firmy. Najistotniejsze w prognozowaniu jest zrozumienie, które metody są najskuteczniejsze w danym kontekście i dostosowanie techniki do specyfiki sektora, w którym firma działa.
Jak prognozować dane w marketingu i łączyć to z biznesem? Najważniejsze wyzwania
Istotne w tym momencie jest zrozumienie perspektyw jakimi rządzi się zarządzanie biznesem i zarządzanie marketingiem:
- Marketing z założenia to działania, które podejmuje się, by promować produkty lub usługi. Jednocześnie jest on w stanie bardzo często dostarczać informację zwrotną na temat tego, w jaki sposób funkcjonuje nasz produkt lub usługa, jak prezentuje się cena, czy jest całość dopasowana do potrzeb końcowego klienta itd., co za tym idzie, funkcjonuje on w sposób nieliniowy. Trudność w tym wszystkim zwiększa to, że jest względnie niska świadomość osób decyzyjnych na temat technik badawczych, statystycznych i zagadnień technicznych, przez co wiele decyzji jest podejmowanych m.in:
- w sposób nieprzemyślany pod kątem potencjalnego ich mierzenia: niewłaściwy dobór kryteriów i metryk, sprowadzanie marketingu wyłącznie do procesu reklamowania, a w zasadzie zakupu mediów (który też z powodu mnogości platform reklamowych, zróżnicowanych definicji i ich zróżnicowanych konstrukcji jest mocno względny)
- życzeniowo: bardzo często estymacje to de facto lista pobożnych celi na potrzeby kreowania rzeczywistości, którą
- zbyt dokładnie: poprzez doszukiwanie się korelacji w miejscach, gdzie ich nie ma
- Biznes z kolei obejmuje nie tylko marketing, ale więcej obszarów (np. logistykę, produkcję), gdzie jest często możliwy dokładny pomiar niektórych procesów (np. produkcyjnych) i ich optymalizacja, co często skutkuje mocno linowym spojrzeniem na chociażby planowanie finansowe (gdzie marketing nie musi wykazywać korelacji między np. zasięgami, a poziomem sprzedaży).
W istocie tworzy się naturalna symbioza, w ramach której biznes od marketingu dostaje dane nie tylko ilościowe (ilość użytkowników, ilość dodań do koszyka, zakupy, poziom retencji), ale także jakościowe (jak chociażby wywiady od użytkowników, satysfakcja z używania produktu, badania społeczne) używane na potrzeby nie tylko planowania, ale także procesu odkrywania produktu i tworzenia szerszej strategii rozwoju biznesu.
Marketing z kolei gros danych pozyskuje reklamowania się, czyli konkretnych produktów reklamowych i systemów analizujących zachowania w czasie rzeczywistym lub historycznie. Biznes z kolei pozyskuje dane chociażby z produkcji, by np. oszacować, ile będzie kosztować potencjalny pokrycie podaży w odpowiedzi na popyt, o którym poinformował marketing.
Reklamy jako jedno z krytycznych źródeł (wbrew przeciwstawnej, obiegowej opinii, która jest w moim mniemaniu błędna) informacji rządzą się swoimi prawami, w ramach których m.in.:
- dostawcy powierzchni reklamowej konkurują ze sobą, co nie sprzyja wymianie informacji między systemami w celu np. atrybuowania ścieżki użytkownika;
- potrafią być rozbieżne pojęcia, np. w zakresie tego, co jest konwersją lub wyświetleniem (a może być błędnym sygnałem co do określania chociażby potencjalnego momentum sprzedażowego na podstawie danych historycznych);
- nie są udostępniane niektóre informacji, czego przyczyny są różne — od tego, że informacje te mogą być faktycznie niepotrzebne, poprzez indywidualne ustalenia, kończąc na tym, że dany produkt z przyczyn bliżej nieokreślonych konkretnych metryk nie udostępnia;
Istotnym elementem jest to, że niektórych zachowań nie można pomierzyć, na co wpływ mają regulacje prawne i zmiany technologiczne, które chociażby blokują przesyłanie niezbędnych danych przez użytkowników.
Znając już podstawy tego, w jaki sposób można określać prognozy oraz ryzyka z nich wynikających, można przejść do tego, w jaki sposób nowoczesne narzędzia marketingowe, w tym Google Analytics 4, przewidują rezultaty.
Jak działa prognozowanie w Google Analytics 4?
Google w narzędziu Google Analytics 4 dokonał implementacji metryk predykcyjnych, które na podstawie danych z sesji użytkowników i (co jest warte zaznaczenia i zapamiętania) zamkniętego modelu od Google prognozuje:
- Prawdopodobieństwo zakupu: Prawdopodobieństwo, że użytkownik, który był aktywny w ciągu ostatnich 28 dni, wywoła w ciągu najbliższych 7 dni zarejestrowanie określonego zdarzenia konwersji.
- Prawdopodobieństwo rezygnacji: Prawdopodobieństwo, że użytkownik, który w ciągu ostatnich 7 dni był aktywny w witrynie lub aplikacji, nie będzie aktywny w ciągu najbliższych 7 dni.
- Prognozowane przychody: Przychody oczekiwane w ciągu najbliższych 28 dni ze wszystkich konwersji polegających na zakupie, które przypuszczalnie wykona użytkownik aktywny w ostatnich 28 dniach.
Dzięki temu można stworzyć dedykowaną grupę odbiorców, którzy np. w danym przedziale czasu mają największe prawdopodobieństwo na zakup, przez co można skierować na nią specjalny komunikat marketingowy poprzez Google Ads.
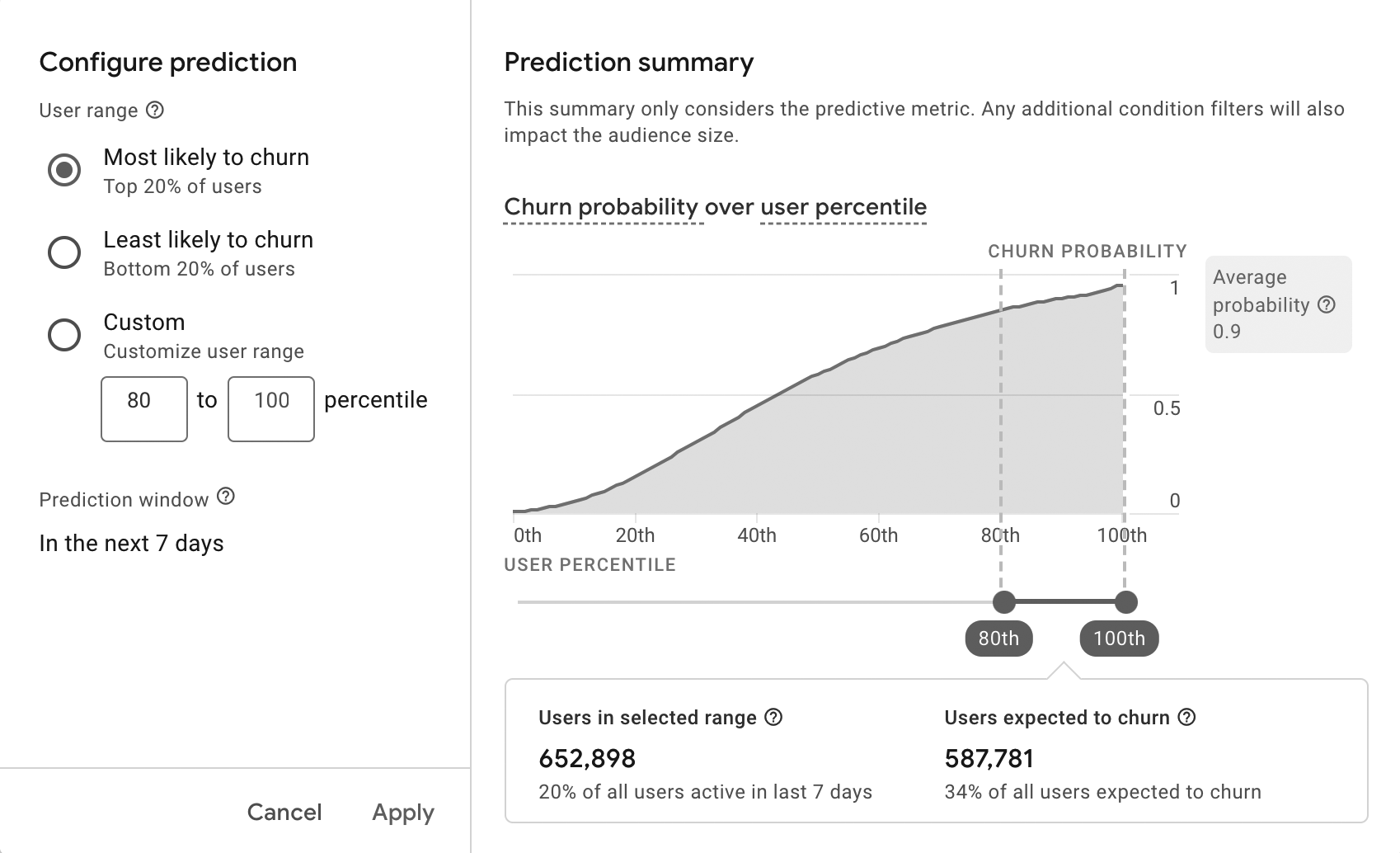
Aby skutecznie trenować modele prognozujące, Google Analytics wymaga spełnienia tych kryteriów:
- Minimalnej liczby pozytywnych i negatywnych przykładów użytkowników skłonnych do zakupów lub rezygnacji. Wymagane jest, aby przez 7 kolejnych dni przypadających w ciągu ostatnich 28 dni co najmniej 1000 powracających użytkowników spełniło odpowiedni warunek prognostyczny (zakup lub rezygnacja) i co najmniej 1000 powracających użytkowników nie spełniło tego warunku.
- Utrzymywania przez pewien czas odpowiedniej jakości modeli prognostycznych
- Aby kwalifikować się do korzystania z danych dotyczących prawdopodobieństwa zakupu i prognozowanych przychodów, usługa musi wysyłać zdarzenia zakupu
Dane prognozowane w przypadku każdego kwalifikującego się modelu będą generowane raz dziennie dla każdego aktywnego użytkownika. Jeśli jakość modelu w usłudze spadnie poniżej minimalnego progu, Google Analytics przestanie aktualizować odpowiednie prognozy i mogą się one stać niedostępne. Niezbędne jest w takiej sytuacji włączenie funkcji Modeling contributions & business insights z sekcji Data sharing.
Warto pamiętać o modelowaniu behawioralnym, które jest mocno powiązanym mechanizmem służącym do minimalizowania niedogodności związanych ze zmianami protokołów prywatności (czyli estymowania tego, ile np. użytkowników odwiedza nasz serwis), a następnie prognozowania: w końcu w taki sposób dostajemy informacje, na podstawie których trenujemy modele, warto więc by były jak najbardziej dokładne (czyli były tak bardzo prawdopodobne jak to możliwe). Oprócz samego wdrożenia Google Tag Manager Server-Side rekomenduję (co jest również wymagane na terenie EOG) sprawdzić, czy consent mode za pomocą Consent Management Platform jest prawidłowo wdrożony.
